Алгоритмы - Разработка и применение - 2016 год
Подсчет инверсий - Разделяй и властвуй
Глава началась с обсуждения методов разрешения некоторых распространенных рекуррентностей. В оставшейся части главы будет продемонстрировано применение принципа “разделяй и властвуй” к задачам из разных областей; информация, представленная в предыдущих разделах, будет использоваться для ограничения времени выполнения этих алгоритмов. Сначала мы увидим, как разновидность метода сортировки слиянием используется для решения задачи, не связанной напрямую с сортировкой чисел.
Задача
Следующая задача встречается при анализе ранжирования, которое начинает играть важную роль во многих современных областях. Например, некоторые сайты применяют метод, называемый совместной фильтрацией, чтобы сопоставить ваши предпочтения (книги, кино, рестораны) с предпочтениями других людей в Интернете. Обнаружив других людей с “похожими” вкусами (которые определяются сравнением оценок, присвоенных ими и вами разным вещам), сайт рекомендует новые ресурсы, которые понравились вашим “единомышленникам”. Другое практическое применение встречается в инструментах метапоиска, которые выполняют один запрос в разных поисковых системах, а потом пытаются синтезировать результаты на основании сходств и различий между рангами, полученными от разных поисковых систем.
Центральное место в таких приложениях занимает задача сравнения двух ранжировок. Вы оцениваете множество из n фильмов, а система совместной фильтрации по своим базам данных ищет других людей с “похожими” оценками. Но как измерить сходство оценок двух людей на числовом уровне? Очевидно, идентичные оценки очень похожи, а полностью противоположные сильно различаются; нужна некая метрика, способная выполнять интерполяцию на середине шкалы.
Рассмотрим задачу сравнения двух ранжировок набора фильмов: вашей и чьей- то еще. Естественный метод — пометить фильмы от 1 до n в соответствии с вашей ранжировкой, затем упорядочить эти метки в соответствии с ранжировкой другого человека и посмотреть, сколько пар “нарушает порядок”. Более конкретная формулировка задачи выглядит так: имеется последовательность из n чисел a1, ..., an; предполагается, что все числа различны. Требуется определить метрику, которая сообщает, насколько список отклоняется от упорядочения по возрастанию; значение метрики должно быть равно 0, если a1 < a2 < ...< an, и должно быть тем выше, чем сильнее нарушен порядок чисел.
Естественное количественное выражение этого понятия основано на подсчете инверсий. Мы будем говорить, что два индекса i <j образуют инверсию, если аi > аj, то есть если два элемента аi и аj идут “не по порядку”. Нужно определить количество инверсий в последовательности a1, ..., аn.
Чтобы вы лучше поняли смысл определения, рассмотрим пример с последовательностью 2, 4, 1, 3, 5. В нем присутствуют три инверсии: (2, 1), (4, 1) и (4, 3). Также существует элегантный геометрический способ наглядного представления инверсий, изображенный на рис. 5.4: сверху записывается последовательность входных чисел в порядке, в котором они заданы, а ниже — эти же числа, упорядоченные по возрастанию. Затем каждое число соединяется отрезком со своей копией в нижнем списке. Каждая пересекающаяся пара отрезков соответствует одной паре, находящейся в обратном порядке в двух списках, — иначе говоря, инверсии.

Рис. 5.4. Подсчет инверсий в последовательности 2, 4, 1, 3, 5. Каждая пересекающаяся пара отрезков соответствует паре, находящейся в обратном порядке во входном и упорядоченном списках, — иначе говоря, инверсии
Обратите внимание, как количество инверсий плавно интерполируется между полным совпадением (когда последовательность упорядочена по возрастанию, инверсий нет) и полным несовпадением (если последовательность упорядочена по убыванию, каждая пара образует инверсию и общее количество инверсий равно ![]() ).
).
Разработка и анализ алгоритма
Как проще всего посчитать инверсии? Разумеется, можно проверить каждую пару чисел (аi, аj) и определить, образуют ли они инверсию; проверка займет время O(n2).
Сейчас мы покажем, как подсчитать инверсии намного быстрее, за время O(n log n). Так как возможно квадратичное количество инверсий, такой алгоритм должен быть способен подсчитать инверсии без проверки отдельных инверсий. Общая идея состоит в применении стратегии (√) из раздела 5.1. Мы назначаем m = [п/2| и делим список на две части: а1, ..., аm и аm+1, ..., аn. Сначала количество инверсий подсчитывается в каждой половине по отдельности, а затем считаются инверсии (аi, аj) для двух чисел, принадлежащих разным половинам; хитрость в том, что это нужно сделать за время O(n), если мы хотим применить (5.2). Обратите внимание: инверсии “первая половина/вторая половина” имеют очень удобную форму: они представляют собой пары (аi, аj), в которых аi находится в первой половине, аj находится во второй половине и аi > аj.
Чтобы упростить подсчет инверсий между половинами, мы заставим алгоритм также рекурсивно сортировать числа в двух половинах. Некоторое возрастание объема работы на шаге рекурсии (сортировка и подсчет инверсий) упростит “объединяющую” часть алгоритма.
Итак, главной частью процесса станет процедура “слияния с подсчетом”. Предположим, мы рекурсивно отсортировали первую и вторую половины списка и подсчитали инверсии в каждой половине. Теперь имеются два отсортированных списка A и B, содержащих первую и вторую половины соответственно. Мы хотим объединить их с построением одного отсортированного списка C, одновременно подсчитав пары (a, b), у которых a ∈ A, b ∈ B, и a > b. По приведенному выше определению это именно то, что необходимо для “объединяющего” шага, вычисляющего количество инверсий между половинами.
Эта задача тесно связана с более простой задачей из главы 2, в которой был сформирован соответствующий “объединяющий” шаг для сортировки слиянием: тогда у нас были два отсортированных списка A и B, которые нужно было объединить в один отсортированный список за время O(n). На этот раз нужно сделать кое- что еще: не только построить один отсортированный список из A и B, но и подсчитать количество “инвертированных пар” (a, b), для которых a ∈ A, b ∈ B, и a > b.
Как выясняется, это делается практически так же, как для слияния. Процедура “слияния с подсчетом” проходит по отсортированным спискам A и B, удаляя элементы от начала и присоединяя их к отсортированному списку C. На каждом конкретном шаге для каждого списка доступен указатель Current, обозначающий текущую позицию. Предположим, эти указатели в настоящее время указывают на элементы ai и bj. За один шаг мы сравниваем элементы ai и bj, удаляем меньший элемент из списка и присоединяем его в конец списка C.
Со слиянием понятно, но как подсчитать количество инверсий? Так как списки A и B отсортированы, отслеживать количество обнаруженных инверсий на самом деле очень просто. Каждый раз, когда элемент a. добавляется к C, новые инверсии не возникают, так как ai меньше всех элементов, оставшихся в списке B, и должен предшествовать им всем. С другой стороны, если элемент bj присоединяется к списку C, значит, он меньше всех оставшихся элементов A и должен следовать после них всех, поэтому счетчик инверсий увеличивается на количество элементов, оставшихся в A. Это центральная идея алгоритма: за постоянное время учитывается потенциально высокое количество инверсий. Процесс проиллюстрирован на рис. 5.5.
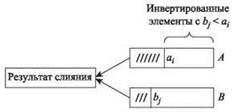
Рис. 5.5. Слияние двух отсортированных списков с одновременным подсчетом инверсий между ними
Ниже приведено описание алгоритма на псевдокоде.

Время выполнения алгоритма слияния с подсчетом может быть ограничено аргументом, аналогичным тому, который использовался для исходного алгоритма слияния в сортировке слиянием: каждая итерация цикла выполняется за постоянное время, и при каждой итерации в выходной список добавляется элемент, который исключается из рассмотрения. Следовательно, количество итераций не может превышать сумму исходных длин A и B, а значит, общее время выполнения составляет O(n).
Процедура используется в рекурсивном алгоритме, который одновременно сортирует и подсчитывает количество инверсий в списке L.

Так как слияние с подсчетом выполняется за время O(n), время выполнения T(n) полной процедуры сортировки с подсчетом удовлетворяет рекуррентному отношению (5.1). Из (5.2) следует (5.7).
(5.7) Алгоритм сортировки с подсчетом i правильно сортирует входной список и подсчитывает количество инверсий; для списка с n элементами он выполняется за время O(n log n).