Информатика - Новый полный справочник для подготовки к ОГЭ
Кодирование и декодирование при передаче информации - Передача информации - ИНФОРМАЦИОННЫЕ ПРОЦЕССЫ
Конспект
Равномерный и неравномерный коды
При передаче информации часто возникает необходимость в особой форме кодирования информации. Как правило, это делается для ускорения передачи информации или для исправления ошибок, возникающих в процессе передачи.
Основной способ кодирования при передаче информации — такой же, как и при представлении информации в компьютерном виде. То есть, каждому передаваемому символу ставится в соответствие определённый код. Этот код известен передатчику (его принято называть источник) и приёмнику. Источник преобразует передаваемые символы в соответствующие коды (кодирует информацию), коды передаются по каналу связи в виде сигналов, после чего приёмник преобразует полученные коды в символы (декодирует информацию). Последовательность сигналов, которая соответствует передаваемому символу, называется кодовым словом. То есть, код, используемый при передаче для кодирования и декодирования информации, состоит из кодовых слов.
Коды, которые присваиваются символам для передачи, могут быть равномерными или неравномерными. Равномерным называется код, у которого длина каждого кодового слова одинаковая. Неравномерным называется код, у которого хотя бы у двух кодовых слов длины различаются.
В обоих случаях процесс кодирования передаваемого сообщения одинаков — каждому передаваемому символу по очереди из кодовой таблицы выбирается его кодовое слово, и это кодовое слово передаётся по каналу связи.
Пример равномерного кода:
|
Символ |
А |
Б |
В |
Г |
Д |
|
Код символа |
000 |
001 |
010 |
011 |
100 |
Пример неравномерного кода:
|
Символ |
А |
Б |
В |
Г |
Д |
|
Код символа |
000 |
001 |
00 |
1 |
10 |
При декодировании неравномерного кода основная проблема — как разбить входящую последовательность на кодовые слова. Ведь не известно, на последовательности какой длины нужно разбить последовательность (длины кодовых слов у разных символов разные).
Префиксный код и дерево декодирования
Самый простой способ, при котором задача определения длины кодовых слов решается просто — использовать для передачи префиксный код.
Для префиксного кода должно выполняться следующее правило: никакое кодовое слово не должно быть началом никакого другого кодового слова. Если это правило выполняется, то для такого кода возможно построить очень удобную для декодирования конструкцию — дерево декодирования. Как правило, количество передаваемых через канал связи сигналов равно двум, поэтому дерево декодирования является двоичным деревом. Если передают большее количество сигналов (например, К),у то и дерево используется K-ичное. На рёбрах этого дерева записываются передаваемые сигналы, а листьями являются декодируемые символы.
Пример префиксного кода:
|
Символ |
А |
Б |
В |
Г |
Д |
|
Код символа |
100 |
11 |
01 |
101 |
00 |
Приведём алгоритм построения дерева декодирования. Рассмотрим его на примере префиксного кода, только что приведённого в таблице в качестве примера.
|
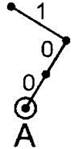
1. Нарисуем корень дерева — точку, от ко- ^ торой будет “расти” наше дерево и от которой впоследствии будет начинаться декодирование каждого следующего символа. |
|
|
2. Возьмём кодовое слово первого символа (в нашем примере — это кодовое слово 100 символа А). Будем рисовать от корня ветки дерева, добавляя для каждого сигнала кодового слова (в нашем случае это 0 и 1) ветку налево, если этот сигнал 0, и ветку направо, если это сигнал 1 (можно и наоборот, но желательно делать это по общему правилу, чтобы не запутаться). В данном случае сначала рисуем ветку вправо (первый символ — кодового слова 100). Затем два раза рисуем ветку влево (второй и третий сигнал кодового слова 100). На каждой рисуемой ветке пишем соответствующий ей сигнал — 0 для веток налево и 1 для веток направо. Лист дерева мы специально обвели в кружок, чтобы в дальнейшем не перепутать его с узлом дерева (и не нарисовать случайно из этой вершины новую ветку). Рядом с листом пишем символ, который соответствует этому листу дерева (символ А). |
|
|
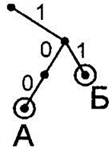
3. Проделаем такую же процедуру для следующего символа (это символ Б, его кодовое слово — 11). Первая ветка (вправо, соответствующая сигналу 1) от корня дерева уже нарисована. Просто “движемся” вдоль ветки право. Вторую ветку рисуем от этой точки вправо (второй сигнал кодового слова 11). Не забываем подписать эту ветку (цифрой 1). Так же обводим получившийся лист в кружок и подписываем его кодируемой буквой Б. |
|
|
4. Ту же операцию повторим для следующего символа — В. Его кодовое слово 01. Нарисуем от корня одну ветку налево (для первого сигнала (0) кодового слова 01). Затем от её конца добавим одну ветку направо (для второго сигнала (1) кодового слова 01). Не забываем подписывать ветки соответствующими цифрами и обвести в кружок получившийся лист, подписав его кодируемой буквой В. |
|
|
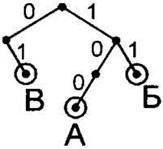
5. Для следующего символа — Г (кодовое слово 101) повторяем операцию. Для первых двух сигналов его кодового слова (1 и 0) от корня дерева уже нарисованы соответствующие ветки. Просто “движемся” вдоль них от корня. Потом рисуем от узла, до которого мы “доехали” таким образом (по пути от корня дерева сначала по ветке 0, затем по ветке 1) ветку, соответствующую оставшемуся сигналу (остался сигнал 1, ветка вправо). Подписываем ветку. Обводим в кружок лист. Подписываем его буквой Г. |
|
|
6. Для оставшегося символа — Д, кодовое слово 00 — повторяем процедуру. От корня дерева сначала “движемся” влево по ветке 0, потому что нужная нам ветка влево (для первого сигнала 0) уже нарисована. От этого узла добавляем ветку влево. Подписываем ветку. Обводим в кружок лист. Подписываем его буквой Д. |
|
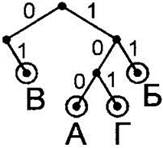
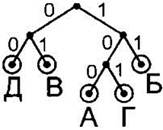
Дерево декодирования готово.
Алгоритм использования дерева декодирования при декодировании следующий:
1. Из канала связи (входного потока приходящих сигналов) приёмник извлекает получаемые сигналы по одному.
2. Получив первый сигнал, приёмник “движется” по дереву декодирования по ветке, подписанной полученным сигналом.
3-а. Если при этом приёмник “доезжает” до листа дерева, приёмник принимает решение, что получен символ, которым подписан этот лист. После этого приёмник считает, что нужно принимать кодовое слово нового символа. То есть, начинает извлекать новые сигналы по одному, получая кодовое слово следующего символа и путешествуя по дереву декодирования от корня.
3-б. Если приёмник “доезжает” до узла дерева (вершины, не являющейся листом), приёмник считает, что очередной символ ещё не получен, извлекает из входного потока новый сигнал и “движется” по дереву декодирования до очередной вершины дерева. После этого снова анализирует, до какого вида вершины он “доехал” (переходит к шагу 3 алгоритма).
Декодирование префиксных кодов очень удобно тем, что это можно делать “на лету”, получая из входного канала сигналы по одному и сразу же производя декодирование, не дожидаясь окончания всего сообщения.
Непрефиксные неравномерные коды
Ещё один способ использования кодов, однозначно декодирующихся — постфиксные коды. Это почти то же самое, что и префиксные коды, только для них должно выполняться правило — никакое кодовое слово не является концом никакого другого кодового слова.
Такие коды обрабатываются точно так же, как и префиксные коды, только они декодируются с конца. Это не очень удобно, так как для декодирования принятого сообщения приходится ждать, пока все сообщение будет принято, а потом уже начинать процесс его декодирования.
Использование при передаче неравномерных префиксных и постфиксных кодов является удобным, но не является обязательным. Коды, которые не обладают свойством префиксности или постфиксности, часто тоже можно однозначно декодировать. Для этого нужно лишь, чтобы не существовала последовательность сигналов, которая может быть двумя разными способами разбита на отдельные кодовые слова.
Задача построения таких кодов не очень проста, а при наличии такой технологии, как префиксные коды, их использование и вовсе не имеет смысла. Однако, эти коды встречаются и их тоже можно декодировать.
Бывают даже коды, которые не допускают однозначного декодирования, но при этом некоторые последовательности, закодированные при помощи подобных кодов, все же возможно декодировать.
Разбор типовых задач
Задача 1. Закодируем равномерным кодом последовательность символов АВГАБ.
Решение
Будем последовательно записывать коды символов в том порядке, в котором они даны в кодируемой последовательности: 000 010 011 000 001. Пробелы мы поставили только для понятности того, что мы делаем. В действительности в результате кодирования получается слитная последовательность. То есть, 000010011000001.
Ответ: 000010011000001.
Если используется равномерный код, процесс декодирования происходит так же просто — приёмник знает длины кодовых слов, он отсчитывает из канала связи количество сигналов, равное длине кодового слова, “заглядывает” в таблицу соответствия передаваемых символов и кодовых слов и извлекает оттуда соответствующий символ. Т.е., получив на вход последовательность 000010011000001, приёмник однозначно разбивает её на кодовые слова одинаковой длины (3) 000 010 011 000 001 и записывает вместо каждого кодового слова соответствующий этому кодовому слову символ: АВГАБ.
Задача 2. Закодируем неравномерным кодом последовательность символов АВГАБ.
Решение
Принцип кодирования точно такой же — последовательно для каждого кодируемого символа из таблицы извлекается кодовое слово и записывается в том же порядке.
В данном случае, получается: 000 001 000 001. Как и в первой задаче, мы поставили пробелы для лучшего понимания, как происходил процесс. В действительности получается сплошная последовательность: 000001000001.
Ответ: 000001000001.
Задача 3. Разведчик передал в штаб радиограмму
• — — • • • — • • — — • • — • — —
В этой радиограмме содержится последовательность букв, в которой встречаются только буквы А, Д, Ж, Л, Т. Каждая буква закодирована с помощью азбуки Морзе. Разделителей между кодами букв нет. Запишите в ответе переданную последовательность букв.
Нужный фрагмент азбуки Морзе приведён ниже.
|
А |
Д |
Ж |
Л |
Т |
|
• — |
— • • |
• — • • |
— |
• • • — |
Решение
Сначала исследуем приведённый код на предмет префиксности. Проверим все кодовые слова маленькой длины, не являются ли они началом какого-нибудь другого кодового слова. Обнаружим, что кодовое слово — (буквы Л) является началом кодового слова — • • (буквы Д). Значит, этот код не префиксный.
Тогда исследуем приведённый код на предмет постфиксности. Проверим все кодовые слова маленькой длины, не являются ли они концами каких-нибудь других кодовых слов. Обнаружим, что кодовое слово — (буквы Л) является концом кодового слова • • • — (буквы Т).
Значит, быстро декодировать последовательность не удастся. Придётся анализировать и рассматривать различные варианты декодирования.
Будем пытаться разбивать радиограмму на отдельные кодовые слова.
Радиограмма начинается на точку. Это значит, что первая буква — А, Ж или Т.
Далее идёт тире. На точку-тире начинается кодовое слово буквы Ж, а также это целиком кодовое слово буквы А. Однако, так как следующим (третьим) полученным символом является тире, мы принимаем решение, что первые два символа (• —) — это буква А, потому что в коде буквы Ж третьим символом должна быть точка, а других кодовых слов, начинающихся на • — —, в коде нет.
Теперь пытаемся разбить на кодовые слова последовательность — • • • — • • — — • • — • — —.
Пусть первый символ последовательности — это кодовое слово буквы Л (—). Тогда последующие символы (• • • —) — это кодовое слово буквы Т (нет другого кодового слова, начинающегося на • •). Следовательно, при попытке выделить в оставшейся последовательности • • — — • • — • — — следующее кодовое слова, мы приходим в тупик. В коде нет кодового слова, начинающегося на • • —. Саму последовательность • • — также нельзя разбить на кодовые слова, так как кодового слова, состоящего из одной точки, в коде нет. Кодовое слово, начинающееся на • •, это только кодовое слово буквы Т (• • • —). В нём после двух точек должна быть снова точка, а не тире, как в начале оставшейся последовательности • • — — • • — • — —.
Значит, наше предположение (что первым символом последовательности — • • • — • • — — • • — • — — является символ Л — неверно).
Из этого делаем вывод, что в начале этой последовательности стоит другое кодовое слово, начинающееся на тире — буква Д (— • •).
Пытаемся выделить следующее кодовое слово в оставшейся последовательности • — • • — — • • — • — —. Пусть это буква А (• —). Тогда у нас остаётся последовательность • • — — • • — • — —, которая, как мы ранее уже выясняли, не декодируется. Следовательно, первая буква — не А, а Ж (• — • •).
Оставшаяся последовательность: — — • • — • — —.
В ней первая буква может быть только Л (нет ни одного кодового слова, начинающегося на — —).
Оставшаяся последовательность: — • • — • — —. Если предположить, что в ней первая буква — снова Л, то остальная последовательность не декодируется (мы уже проверили, что последовательность, начинающаяся с символов • • —, в этом коде быть не может). Значит, первая буква в этой оставшейся последовательности (— • • — • — —) — это буква Д (— • •).
Оставшаяся последовательность: — • — —. Первой буквой может быть только Л (нет кодового слова, начинающегося с — • —). Остаётся • — —, которая может быть разбита на кодовые слова только как • —, — (А, Л).
То есть, общее разбиение исходной последовательности на кодовые слова получилось таким:
![]()
Заменим полученные кодовые слова на соответствующие им символы и получим АДЖЛДЛАЛ.
Ответ: АДЖЛДЛАЛ.
Заметим, что приведённый код в общем случае не допускает однозначного декодирования, потому что в нем последовательность — • • • — может быть разбита на кодовые слова как — • , • • — (то есть декодирована как Д, А), а может быть разбита на кодовые слова как — , • • • — (то есть, декодирована как Л, Т). В данном случае приведённая радиограмма однозначно декодируется, потому что попытка трактовать последовательность — • • • — как два законченных кодовых слова приводит к невозможности декодировать оставшееся сообщение. Приходится считать, что последовательность — • • • —, — это кодовое слово — • •, а оставшиеся символы • —, являются началом другого кодового слова. Поэтому двойственности декодирования не возникает.