Программирование: введение в профессию. 1: Азы программирования - 2016 год
Система типов Паскаля - Язык Паскаль и начала программирования
2.8.1. Встроенные типы и пользовательские типы
Переменные и выражения, которые мы использовали до сих пор, относились к различным типам (integer и longint, real, boolean и некоторым другим), но у всех этих типов есть одно общее свойство: они встроены в язык Паскаль, то есть нам не нужно объяснять компилятору, что это за типы, компилятор о них уже знает.
Встроенными типами дело не ограничивается; Паскаль позволяет нам самим создавать новые типы выражений и переменных. В большинстве случаев новым типам даются имена, для чего используются уже знакомые нам идентификаторы — точно так же, как для уже знакомых нам переменных, констант и подпрограмм; в некоторых случаях используются также анонимные типы, то есть, как следует из названия, типы, которым имя не присваивается, но их использование в Паскале несколько ограничено. Любые типы, вводимые программистом (то есть не являющиеся встроенными), называются пользовательскими типами, потому что их вводит пользователь компилятора; ясно, что таким пользователем является программист, которого, конечно же, не следует путать с пользователем полученной программы.
Для описания пользовательских типов и их имён используются секции описания типов, начинающиеся с ключевого слова type, подобно тому, как секции описания переменных начинаются со слова var. Как и в случае с переменными, секцию описания типов можно расположить в глобальной области либо локально в подпрограмме (между заголовком подпрограммы и её телом). Как и переменные, типы, описанные в подпрограмме, видны только в этой подпрограмме, тогда как типы, описанные вне подпрограмм (то есть в глобальной области) видны в программе с того места, где тип описан, и до конца программы.
Самый простой вариант нового типа — это синоним какого-нибудь типа, который у нас уже есть, в том числе встроенного; например, мы можем описать тип MyNumber как синоним типа real:
![]()
после чего у нас появится возможность описывать переменные типа MyNumber:
![]()
Делать с этими переменными можно всё то же самое, что и с переменными типа real; более того, их можно неограниченно смешивать в выражениях с переменными и другими значениями типа real, присваивать друг другу и т. п. На первый взгляд введение такого синонима может показаться бессмысленным, но иногда оно оказывается полезно. Например, мы можем во время написания какой-нибудь сравнительно сложной программы усомниться в том, какой разрядности целых чисел нам хватит для возникшей локальной задачи; если, к примеру, мы решим, что нам хватит обычных двухбайтных integerов, а потом (уже в процессе тестирования или даже эксплуатации программы) окажется, что их разрядности не хватает и программа работает с ошибками из-за переполнений, то для замены integerов на longintы или даже на int64 нам придётся внимательно просмотреть текст программы, чтобы идентифицировать переменные, которые должны работать с числами большей разрядности, и поменять их типы; при этом мы рискуем что-нибудь упустить или, наоборот, превратить в четырёхбайтную какую-нибудь переменную, для которой достаточно и двух байт.
Некоторые программисты справляются с этой проблемой, как говорится, дёшево и сердито: попросту используют longint всегда и для всего. Но при ближайшем рассмотрении такой подход оказывается не слишком удачным: во-первых, разрядности longint тоже может не хватить и потребуется int64, а во-вторых, иногда бездумное использование переменных разрядности большей, чем требуется, приводит к заметному перерасходу памяти (например, при работе с большими массивами) и замедлению работы программы (если вместо integer использовать int64 в 32-битной системе, скорость работы может упасть в несколько раз).
Введение типов-синонимов позволяет обойтись с этой проблемой более изящно. Допустим, мы пишем симулятор дорожного движения, в котором у каждого объекта, участвующего в нашем моделировании, имеется свой уникальный номер, а ещё бывают нужны циклы, пробегающие все такие номера; при этом мы точно не знаем, хватит нам 32767 объектов для достижения требуемых целей моделирования или не хватит. Вместо того, чтобы гадать, какой использовать тип — integer или longint30, мы можем ввести свой собственный тип, точнее, имя типа:
![]()
Теперь везде, где нам по смыслу требуется хранить и обрабатывать идентификатор объекта симуляции, мы будем использовать имя типа SimObjectld (а не integer), а если вдруг мы поймём, что количество объектов в модели опасно приближается к 32000, мы сможем в одном месте программы — в описании типа SimObjectld — заменить integer на longint, остальное произойдёт автоматически. Кстати, если на протяжении программы нам ни разу не потребуется отрицательное значение идентификатора объекта, мы сможем заменить integer на более подходящий здесь беззнаковый word, и так далее.
2.8.2. Диапазоны и перечислимые типы
Рассмотренные в предыдущем параграфе имена-синонимы, вообще говоря, никаких новых типов не создавали, только вводили новые имена для уже существующих. Этот параграф мы посвятим двум простейшим случаям создания действительно новых типов.
Пожалуй, самым простым случаем, требующим наименьшего количества пояснений, является диапазон целых чисел. Переменная такого типа может принимать целочисленные значения, но не всякие и даже не те, которые обусловлены её разрядностью, а только значения из заданного диапазона. Например, мы знаем, что десятичные цифры могут иметь своим значением число от нуля до девяти; этот факт мы можем отразить, описав соответствующий тип:

Переменная d, описанная таким образом, может принимать всего десять значений: целые числа от нуля до девяти. В остальном с этой переменной можно работать точно так же, как с другими целочисленными переменными.
Уместно будет отметить, что (во всяком случае, для Free Pascal) машинное представление числа в такой переменной совпадает с машинным представлением обычного целого числа, так что размер переменной диапазонного типа оказывается таким же, как размер наименьшей переменной встроенного целого типа, способного принимать все значения заданного диапазона. Так, переменная типа digit10 будет занимать один байт; переменная типа диапазон 15000..15010 будет занимать, как ни странно, два байта, потому что наименьший тип, умеющий принимать все значения из этого дипапазона — это тип integer. Точно так же два байта будет занимать к переменная типа диапазон 60000..60010, поскольку все эти значения может принимать переменная типа word, и так далее. На первый взгляд это кажется несколько странным, ведь оба эти диапазона предполагают всего по 11 различных значений каждый; ясно, что для них хватило бы одного байта. Но дело в том, что, используя в таких ситуациях один байт, компилятор был бы вынужден представлять числа из диапазонов не так, как обычные целые числа, и при каждой арифметической операции над числами из диапазонов был бы вынужден вставлять в машинный код дополнительное сложение или вычитание для приведения машинного представления к виду, обрабатываемому центральным процессором. Ничего невозможного в этом нет, но в современных условиях быстродействие программы практически всегда важнее, чем объём используемой памяти.
В принципе, диапазонные типы не ограничиваются целыми числами; например, мы можем задать подмножество символов:
![]()
К этому вопросу мы вернёмся при изучении понятия порядкового типа. Пока отметим ещё один очень важный момент: при задании диапазона для указания его границ можно использовать только константы времени компиляции (см. § 2.5.2).
Ещё один простой случай пользовательского типа — так называемый перечислимый тип; выражение такого типа может принимать одно из значений, перечисленных явным образом при описании типа. Сами эти значения задаются идентификаторами. Например, для описания цветов радуги мы могли бы задать тип
![]()
![]()
Переменная rc может принимать одно из значений, перечисленных в описании типа; например, можно сделать так:
![]()
Кроме присваивания, значения выражений перечислимого типа можно сравнивать (как на равенство и неравенство, так и на порядок, то есть с помощью операций <, >, <= и >=). Кроме того, для значения перечислимого типа можно узнать предыдущее значение и следующее значение. Это делается встроенными функциями pred и succ; например, при использовании типа RainbowColors из нашего примера выражение pred(yellow) имеет значение orange, а выражение succ(blue) имеет значение indigo. Попытки вычислить значение, предшествующее первому или следующее за последним, ни к чему хорошему не приведут, так что прежде, чем применять функции succ и pred, следует удостовериться, что выражение, используемое в качестве аргумента, не имеет своим значением, соответственно, последнее или первое значение для данного типа.
Отметим, что функции succ к pred определены отнюдь не только для перечислимых типов, но об этом позже.
Значения перечислимого типа имеют номера, которые можно узнать с помощью уже знакомой нам31 встроенной функции ord и которые всегда начинаются с нуля, а номер следующего значения на единицу превосходит номер предыдущего.
В классическом Паскале константы, задающие перечислимый тип, равны только сами себе и ничему иному; предложение “явно задать значение константы в перечислении” с точки зрения классического Паскаля попросту бессмысленно. В то же время современные диалекты Паскаля, включая Free Pascal, под влиянием языка Си (в котором аналогичные константы являются просто целочисленными) несколько видоизменились и позволяют явно задавать номера для констант в перечислениях, порождая странный (если не сказать бредовый) тип, который считается порядковым, но при этом не допускает использования succ и pred и фактически не даёт ничего полезного, ведь (в отличие, опять же, от Си) в Паскале есть средства, специально предназначенные для описания констант времени компиляции, притом не только целочисленных. Рассматривать такие “явные значения номеров” мы не будем, как, впрочем, и многие другие средства, имеющиеся во Free Pascal.
Отметим, что константа, задающая значение перечислимого типа, может быть использована только в одном таком типе, иначе компилятор не смог бы определить тип выражения, состоящего из одной этой константы. Так, описав в программе тип RainbowColors, а потом забыв про него и описав (например, для моделирования сигналов светофора) что-то вроде
![]()
мы получим ошибку. Поэтому программисты часто снабжают константы перечислимых типов префиксами, мнемонически связанными с их типом. Например, мы могли бы избежать конфликта, сделав так:

2.8.3. Общее понятие порядкового типа
Под порядковым типом в Паскале понимается тип, удовлетворяющий следующим условиям:
1. всем возможным значениям этого типа сопоставлены целочисленные номера, причём это сделано неким естественным образом;
2. над значениями этого типа определены операции сравнения, причём элемент с меньшим номером считается меньшим;
3. для типа возможно указать наименьшее и наибольшее значение; для всех значений, кроме набольшего, определено следующее значение, а для всех значений, кроме наименьшего, определено предыдущее значение; порядковый номер предыдущего значения на единицу меньше, а следующего значения — на единицу больше номера исходного значения.
Для вычисления порядкового номера элемента в Паскале предусмотрена встроенная функция ord, а для вычисления предыдущего и следующего элементов — функции pred и succсоответственно. Все эти функции нам уже знакомы, но теперь мы можем перейти от частных случаев к общему и объяснить, что эти функции на самом деле делают и какова их область применения.
Порядковыми типами являются:
• тип boolean; его наименьшее значение false имеет номер 0, а наибольшее значение true — номер 1;
• тип char; номера его элементов соответствуют кодам символов, наименьший элемент — #0, наибольший — #255;
• целочисленные типы, как знаковые, так и беззнаковые32;
• любой диапазонный тип;
• любой перечислимый тип.
В то же время тип real порядковым не является; это вполне понятно, ведь числа с плавающей точкой (фактически это двоичные дроби) не допускают никакой “естественной” нумерации. Функции ord, pred и succ к значениям типа real применять нельзя, это вызовет ошибку при компиляции.
Если говорить в общем, порядковыми в Паскале не являются никакие типы, кроме перечисленных выше, то есть кроме boolean, char, целых (разрядностью до 32 бит включительно), перечислимых типов и диапазонов.
Понятие порядкового типа в Паскале очень важно, поскольку во многих ситуациях допускается использование любого порядкового типа, но не допускается использование никакого другого. Одну такую ситуацию мы уже видели: диапазон можно задать как поддиапазон любого порядкового типа — и никакого другого. В будущем мы столкнёмся также с другими ситуациями, в которых необходимо использовать порядковые типы.
2.8.4. Массивы
Язык Паскаль позволяет создавать сложные переменные, которые отличаются от простых тем, что сами состоят из переменных (разумеется, другого, “более простого” типа). Сложные переменные бывают двух основных видов: массивы и записи; мы начнём с массивов.
Массивом в Паскале называется сложная переменная, состоящая из нескольких переменных одного и того же типа, называемых элементами массива. Для обращения к элементам массива служат так называемые индексы — значения того или иного порядкового типа, чаще всего — обыкновенные целые числа, но не обязательно; индекс записывается в квадратных скобках после имени массива, то есть если, например, a — это переменная типа “массив”, для которого индексами служат целые числа, то a[3] — это элемент массива a, имеющий номер (индекс) 3. В квадратных скобках можно указывать не только константу, но и произвольное выражение соответствующего типа, что позволяет вычислять индексы во время исполнения программы (заметим, без этой возможности массивы не имели бы никакого смысла).
Коль скоро массив — это, по сути, переменная, пусть даже и “сложная”, у этой переменной должен быть тип; его можно, как и другие типы, описать и снабдить именем. Например, если мы планируем использовать в программе массивы из ста чисел типа real, соответствующий тип можно описать так:
![]()
Теперь real100 — это имя типа; переменная такого типа будет состоять из ста переменных типа real (элементов массива), которые снабжены своими номерами (индексами), причём в качестве таких индексов используются целые числа от 1 до 100. Введя имя типа, мы можем описывать переменные этого типа, например:
![]()
Описанные таким образом а и b — это и есть массивы; они состоят из элементов а[1], а[2], ..., a[100], b[1], b[2], ..., b[100] Например, если нам зачем-то понадобится изучать поведение синуса в окрестностях нуля, то для этого мы можем для начала в элементах массива а сформировать последовательность чисел ![]()
![]()
а затем в элементы массива b занести соответствующие значения синуса:
![]()
и, наконец, распечатать всю полученную таблицу:
![]()
Обратите внимание, что здесь мы все операции производим над элементами массивов, а не над самими массивами; но массив при необходимости можно рассматривать и как единое целое, ведь это же переменная. В частности, массивы можно друг другу присваивать:
![]()
но сначала следует хорошо подумать, ведь при таком присваивании вся информация из области памяти, занятой одним массивом, копируется в область памяти, занятую другим массивом, и это может занять сравнительно много времени, особенно если делать это часто — скажем, в каком-нибудь цикле. Точно так же следует соблюдать осмотрительность при передаче массивов в качестве параметра в процедуры и функции; к этому вопросу мы ещё вернёмся. Важно помнить, что присваивать друг другу можно только массивы одного типа; если два массива относятся к разным типам, пусть даже совершенно одинаково описанным, присваивать их будет нельзя.
Как мы уже упоминали, в принципе типу-массиву можно не давать имени, а сразу описывать переменную такого типа; например, мы могли бы поступить так:
![]()
и в условиях простой задачи, в которой больше массивов такого типа не предполагается, мы совершенно не заметим разницы. Но если в какой-то момент, например, локально в какой-нибудь процедуре нам потребуется ещё один такой массив, и мы опишем его:
![]()
то этот массив окажется несовместим с массивами а и b, то есть их нельзя будет присваивать друг другу, несмотря на то, что описаны они совершенно одинаково. Дело в том, что формально они относятся к разным типам: каждый раз, когда компилятор видит такое описание переменной, на самом деле создаётся ещё один тип, просто ему не даётся имени, поэтому в нашем примере первый такой тип оказался создан при описании массивов а и Ь, а второй (пусть точно такой же, но новый) — при описании массива с.
Отдельного внимания заслуживает указание пределов изменения индекса. Синтаксическая конструкция “1..100” определённо что-то напоминает: точно таким же образом описывались диапазонные типы, и это не случайно. Для индексирования массивов в Паскале можно использовать любые порядковые типы, а при описании типа-массива на самом деле задаётся тип, которому должно принадлежать значение индекса, чаще всего это как раз диапазон, но не обязательно. Так, тип геа1100 мы могли бы описать более развёрнуто:
![]()
Здесь мы сначала описываем в явном виде диапазонный тип, снабжая его именем “from1to100”, а потом используем это имя при описании массива. Бывают массивы, индексами которых служат не диапазоны, а что-то иное. Например, если у нас в задаче имеются шарики семи цветов радуги, причём цвет мы обрабатываем с помощью перечислимого типа RainbowColors и нужно в какой-то момент посчитать, сколько есть шариков каждого цвета, то может оказаться удобным массив такого типа:
![]()
Можно в качестве индекса массива использовать и char, и даже boolean:
![]()
Первый из этих типов задаёт массив из 256 элементов (типа integer), соответствующих всем возможным значениям типа char (то есть всем возможным символам); такой массив может понадобиться, например, при частотном анализе текста. Второй тип предполагает два элемента типа real, соответствующих логическим значениям; чтобы понять, где такое странное сооружение может пригодиться, представьте себе геометрическую задачу, связанную с вычислением сумм площадей каких-нибудь фигур, причём суммирование нужно проводить раздельно по фигурам, соответствующим какому-нибудь условию, и по всем остальным.
Массивы оказываются незаменимы в таких задачах, где прямо из условия становится очевидно, что необходимо поддерживать много значений одного и того же типа, различающихся по номерам. Рассмотрим для примера следующую задачу.
В городе N проводили олимпиаду по информатике. Участников ожидалось достаточно много, поэтому было решено, что регистрироваться для участия в олимпиаде они будут прямо в своих школах. Поскольку школ в городе всего 67, а от каждой школы в олимпиаде участие могут принять не больше двух-трёх десятков учеников, организаторы решили устроить нумерацию карточек участников следующим образом: номер состоит из трёх или четырёх цифр, причём две младшие цифры задают номер участника среди учеников одной и той же школы, а старшие одна или две цифры — номер школы; например, в школе № 5 будущим участникам олимпиады выдали карточки с номерами 501, 502, ..., а в школе № 49 — с номерами 4901, 4902 и т.д.
Школьники, приехавшие на олимпиаду, предъявляли свои карточки организаторам, а организаторы заносили в текстовый файл olymp.txt строки следующего вида: сначала набирали номер карточки, а потом, через пробел, — фамилию и имя участника. Естественно, участники появлялись на олимпиаде в совершенно произвольном порядке, так что файл мог содержать, например, такой фрагмент:

В день олимпиады в городе проходил футбольный матч между популярными командами, в результате чего не все ученики, зарегистрировавшиеся в своих школах, в итоге приехали на олимпиаду — некоторые предпочли пойти на стадион. Надо узнать, из каких школ прибыло наибольшее количество участников.
На первый взгляд с решением этой задачи могут возникнуть сложности, ведь мы пока не разбирали, как в Паскале работать с файлами и как обрабатывать строки, но это, как ни странно, не нужно. Имена учеников мы можем проигнорировать, ведь нам нужен только номер школы, который извлекается из номера карточки участника путём целочисленного деления этого номера на 100. Что касается файлов, то недостаток знаний мы можем компенсировать умением перенаправлять поток стандартного ввода: в программе мы будем читать информацию обычными средствами — оператором readln (прочитав число, этот оператор сбросит всю информацию до конца строки, что нам и требуется), а запускать программу будем с перенаправлением стандартного ввода из файла olymp.txt. Чтение мы будем выполнять до тех пор, пока файл не закончится; как это делается, мы уже знаем из § 2.7.3.
В процессе чтения нам придётся подсчитывать количество учеников для каждой из 67 школ города, то есть понадобится одновременно поддерживать 67 переменных; массивы придуманы как раз для таких ситуаций. На всякий случай число 67 вынесем в начале программы в именованную константу. Точно так же в именованную константу вынесем максимально допустимое количество учеников из одной школы; оно соответствует числу, на которое нужно делить номер карточки для получения номера школы (в нашем случае это 100):
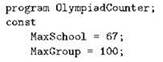
В принципе, массив в нашей программе нужен ровно один, так что можно было бы оставить его тип анонимным, но мы так делать не будем и опишем тип нашего массива, снабдив его именем:
![]()
В качестве переменных нам потребуется, во-первых, сам массив; во-вторых, нам нужны будут целочисленные переменные для выполнения циклов по этому массиву, для чтения номеров карточек из потока ввода и для хранения номера школы. Опишем эти переменные:
![]()
Теперь мы можем написать главную часть программы, которую начнём с того, что обнулим все элементы массива; в самом деле, пока мы ни одной карточки участника не видели, так что количество участников из каждой школы должно быть равно нулю:
![]()
Теперь нам нужно организовать цикл чтения информации. Как мы уже договорились, выполнять чтение будем до тех пор, пока функция eof не скажет нам, что читать больше нечего; для чтения мы воспользуемся оператором readln. На всякий случай мы не будем предполагать, что данные в стандартном потоке ввода корректны, ведь файл набирали люди, а людям свойственно ошибаться. Поэтому после каждого введённого числа мы будем проверять, удалось ли нашему оператору readln корректно преобразовать введённую цепочку символов в число. Напомним, что это делается с помощью функции IOResult. Чтобы это работало, нужно не забыть сообщить компилятору о нашем намерении обрабатывать ошибки ввода-вывода самостоятельно; это, как мы знаем, делается директивой {$I-}.
Наконец, последний важный момент состоит в том, что, прежде чем обращаться к элементу массива, пытаясь его увеличить, нужно обязательно проверить, что полученный номер школы является допустимым. Например, если оператор случайно ошибся и ввёл какой-нибудь недопустимый номер карточки вроде 20505, то при попытке обратиться к элементу массива с номером 205 наша программа завершится аварийно; допускать этого не следует, гораздо правильнее сообщить пользователю, что мы обнаружили в файле недопустимый номер школы.
Если обнаружена любая ошибка, обработку файла на этом стоит прекратить, всё равно нам уже не получить правильных результатов; программу можно завершить, сообщив при этом операционной системе, что мы завершаемся неуспешно. Полностью наш цикл чтения будет выглядеть так:

Следующий этап обработки полученной информации — определить, какое количество учеников из одной и той же школы является “рекордным”, то есть попросту определить максимальное значение среди элементов массива Counters. Это делается следующим образом. Для начала мы объявим “рекордной” школу № 1, сколько бы учеников оттуда ни прибыло (даже если ни одного). Для этого мы её номер, то есть число 1, занесём в переменную n; эта переменная у нас будет хранить номер школы, которая к настоящему моменту (пока что) считается “рекордной”. Затем мы просмотрим информацию по всем остальным школам, и каждый раз, когда число учеников из очередной школы превышает число учеников из той, которая до сей поры считалась “рекордной”, мы будем присваивать переменной n номер новой “рекордной” школы:

К моменту окончания этого цикла все счётчики будут просмотрены, так что в переменной n окажется номер одной из тех школ, откуда приехало максимальное количество учеников; в общем случае таких школ может быть больше одной (например, на олимпиаду могло приехать по 17 участников из школ № 3, № 29 и № 51, а из всех остальных школ — меньше). Остаётся сделать, собственно, то, ради чего написана программа: напечатать номера всех школ, из которых приехало ровно столько учеников, сколько и из той, номер которой находится в переменной n. Это сделать совсем просто: просматриваем все школы по порядку, и если из данной школы приехало столько же учеников, сколько и из nной, то печатаем её номер:
![]()
Остаётся только завершить программу словом end и точкой. Целиком текст программы получается такой:

Отметим, что переменные-массивы при их описании можно инициализировать, то есть задавать начальные значения их элементов. Эти значения перечисляют в круглых скобках через запятую, например:

2.8.5. Тип запись
Как мы уже упоминали, Паскаль поддерживает два вида сложных типов — массивы и записи. Если переменная типа массив, как мы видели, состоит из переменных (элементов) одинакового типа, различающихся номером (индексом), то переменная типа запись состоит из переменных, называемых полями, типы которых в общем случае различны. В отличие от элементов массива, поля записи различаются не номерами, а именами.
К примеру, на соревнованиях по спортивному ориентированию каждый контрольный пункт, который необходимо пройти участникам, может характеризоваться, во-первых, его номером; во-вторых, его координатами, которые можно записывать в виде дробных чисел в градусах широты и долготы (по умолчанию можно считать, например, что широты у нас северные, долготы восточные, а южные широты и западные долготы обозначать отрицательными значениями); в-третьих, некоторые контрольные пункты могут быть “скрытыми”, то есть не отражёнными на картах, выдаваемых участникам соревнований; обычно местоположение таких пунктов оказывается известно при взятии других пунктов; наконец, каждому пункту сопоставляется размер штрафа за его невзятие — обычно это целое число, выраженное в минутах. Для представления информации о контрольном пункте можно создать специальный тип:

Здесь идентификатор Checkpoint — это имя нового типа, record — ключевое слово, обозначающее запись; далее идёт описание полей записи в таком же формате, в каком мы описываем переменные в секциях var: сначала имена переменных (в данном случае полей) через запятую, затем двоеточие, имя типа и точка с запятой. Переменная типа Checkpoint будет, таким образом, представлять собой запись с целочисленными полями n и penalty, полями latitude и longitude типа real и полем hidden логического типа. Опишем такую переменную:
![]()
Переменная ср занимает столько памяти, сколько нужно, чтобы разместить все её поля; сами эти поля доступны “через точку”: коль скоро ср есть имя переменной типа “запись”, то ср.п, cp.latitude, cp.longitude, cp.hidden и cp.penalty — это её поля, которые тоже, конечно же, представляют собой переменные. Например, мы можем занести в переменную cp данные какого-нибудь контрольного пункта:
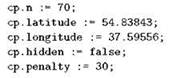
Как и в случае с массивами, при работе с записью большинство действий, если не все, производятся над её полями; единственное, что можно сделать с самой записью как единым целым — это присваивание.
2.8.6. Конструирование сложных структур данных
Полем записи вполне может быть массив и даже другая запись (хотя этот вариант нужен сравнительно редко). Точно так же и запись может быть элементом массива; например, мы могли бы в начале программы задать константу, обозначающую общее количество контрольных пунктов:
![]()
и после описания типа Checkpoint (как это сделано в предыдущем параграфе) описать тип для массива, в который можно занести информацию обо всех контрольных пунктах дистанции и описать переменную такого типа:
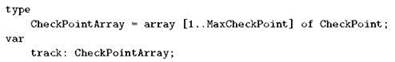
Получившаяся в переменной track структура данных соответствует нашему представлению о таблице. Когда мы строим таблицу на бумаге, обычно сверху мы выписываем названия её столбцов, а дальше у нас идут строки, содержащие как раз “записи”. В только что построенной структуре данных роль заголовка таблицы с названиями столбцов играют имена полей — n, latitude, longitude, hidden и penalty. Строкам таблицы соответствуют элементы массива: track[1], track[2], и т.д., каждый из которых представляет собой запись типа Checkpoint, а отдельная клетка таблицы оказывается полем соответствующей записи: track[7].latitude, track[63].hidden и т. п.
Элементом массива также может быть и другой массив. Такая ситуация встречается столь часто, что имеет и собственное название — “многомерный массив”, и специальный синтаксис для её описания: при задании типа массива мы можем в квадратных скобках написать не один тип индекса, а несколько, разделив их запятой. Например, следующие описания типов эквивалентны:
![]()
Точно так же при обращении к элементу многомерного (в данном случае — двумерного) массива можно с одинаковым успехом написать a[2][6] и a[2,6].
Наиболее очевидное применение многомерных массивов — для представления математического понятия матрицы; так, при решении системы линейных уравнений нам могла бы потребоваться какая-нибудь матрица вроде
![]()
Многомерные массивы тоже могут быть полями записей, как и записи могут быть их элементами. Формальных ограничений на глубину вложенности описаний типов в Паскале не существует, но увлекаться этим всё же не стоит: память компьютера отнюдь не бесконечна, и вдобавок некоторые конкретные ситуации могут накладывать дополнительные ограничения. Например, прежде чем делать огромный массив локальной переменной в подпрограмме, следует десять раз подумать: локальные переменные располагаются в стековой памяти, которой может оказаться гораздо меньше, чем вы ожидали.
2.8.7. Пользовательские типы и параметры подпрограмм
При передаче в подпрограммы значений (и переменных), имеющих пользовательские типы, следует учитывать некоторые моменты, не вполне очевидные для начинающих.
Прежде всего следует отметить, что при описании параметров в заголовках подпрограмм запрещено использование анонимных типов. Иначе говоря, вызовет ошибку попытка написать что-то вроде следующего:
![]()
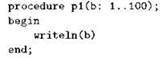
Чтобы тип можно было использовать при передаче параметра в подпрограмму, этот тип обязательно нужно описать в секции описания типов и снабдить именем:

То же самое можно сказать и о возврате значения из функции: для этого годятся только типы, имеющие имена.
Второй момент, достойный упоминания, касается передачи в подпрограммы (и возврата из функций) значений сложных типов, занимающих большое количество памяти. Паскаль, в принципе, не запрещает этого делать: можно передать в процедуру большую запись или массив, и программа успешно пройдёт компиляцию и даже будет как-то работать. Необходимо только помнить две вещи. Во-первых, как уже упоминалось, локальные переменные (в том числе параметры-значения) располагаются в памяти в области аппаратного стека, где может быть мало места. Во-вторых, само по себе копирование больших объёмов данных занимает ненулевое время, что можно замечательно ощутить, если делать такие вещи часто — например, вызывать какую-нибудь подпрограмму в цикле, каждый раз передавая ей параметром по значению массив большого размера.
Поэтому по возможности следует воздерживаться от передачи в подпрограммы значений, занимающих значительный объём памяти; если же этого никак не удаётся избежать, то лучше будет использовать var-параметр, даже если вы не собираетесь в передаваемой переменной ничего менять. Дело в том, что при передаче любого значения через var-параметр никакого копирования не происходит. Мы уже говорили, что локальное имя (имя var-параметра) на время работы подпрограммы становится синонимом той переменной, которая указана при вызове; отметим, что на уровне машинного кода этот синоним реализуется путём передачи адреса, а адрес занимает не так много места — 4 байта на 32-битных системах и 8 байт на 64-битных.
Итак, если вы работаете с переменными, имеющими значительный размер, лучше всего вообще не передавать их параметрами в подпрограммы; если это всё же приходится делать, то их следует передавать как var-параметры; и лишь в совсем крайнем случае (который обычно не возникает) можно попытаться передать такую переменную по значению и надеяться, что всё будет хорошо.
Конечно, возникает вопрос, какие переменные считать имеющими “значительный размер”. Конечно, размер в 4 или 8 байт “значительным” не является. Можно не слишком беспокоиться по поводу копирования 16 байт и даже 32, но вот если размер вашего типа ещё больше — то передача объектов такого типа по значению сначала становится “нежелательной”, потом где-то на уровне 128 байт — “крайне нежелательной”, а где-нибудь на уровне 512 байт — недопустимой, несмотря на то, что компилятор возражать не станет. Если же вам придёт в голову передать по значению структуру данных, занимающую килобайт или больше, то постарайтесь хотя бы никому не показывать ваш исходный текст: велик риск, что, увидев такие выкрутасы, с вами больше не захотят иметь дела.
2.8.8. Преобразования типов
Если в программе описать переменную типа real, а затем присвоить ей целое число:
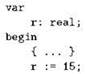
то, как ни странно, ничего страшного при этом не произойдёт: в переменную r будет занесено совершенно корректное и естественное для такой ситуации значение 15.0. Точно так же можно переменной типа real присвоить значение произвольного целочисленного выражения, в том числе вычисляемого во время исполнения программы; присвоено в итоге окажется, разумеется, число с плавающей точкой, целая часть которого равна значению выражения, а дробная часть — нулю.
Начинающие зачастую не задумываются о том, что на самом деле происходит в такой ситуации; между тем, как мы знаем, машинные представления целого числа 15 и числа с плавающей точкой 15.0 друг на друга совершенно не похожи. Обычное присваивание, при котором в переменную заносится значение выражения точно такого же типа, сводится (на уровне машинного кода) к простому копированию информации из одного места в другое; присваивание целого числа переменной с плавающей точкой так реализовать нельзя, необходимо преобразовать одно представление в другое. Так мы приходим к понятию преобразования типов.
Случай “магического превращения” целого в дробное относится к так называемым неявным преобразованиям типов; так говорят, когда компилятор преобразует тип выражения сам, без прямых указаний со стороны программиста. Возможности неявных преобразований в Паскале довольно скромные: разрешается неявно преобразовывать числа различных целочисленных типов друг в друга и в числа с плавающей точкой, плюс можно превращать друг в друга сами числа с плавающей точкой, которых тоже есть несколько типов — single, double и extended, а знакомый нам realявляется синонимом одного из трёх, в нашем случае — double. Чуть позже мы встретимся с неявным преобразованием символа в строку, но этим всё закончится; больше компилятор ничего по своей инициативе преобразовывать не станет. Неявные преобразования встречаются не только при присваивании, но и при вызове подпрограмм: если какая-нибудь процедура ожидает параметр типа real, мы совершенно спокойно можем указать при вызове целочисленное выражение, и компилятор нас поймёт.
Заметим, что целое число компилятор согласен “магически превратить” в число с плавающей точкой, но делать преобразование в обратную сторону он откажется наотрез: если мы попытаемся присвоить целочисленной переменной значение, имеющее тип числа с плавающей точкой, при компиляции будет выдана ошибка. Дело здесь в том, что преобразовать дробное в целое можно разными способами, и компилятор отказывается делать за нас выбор такого способа; мы должны указать, каким конкретно способом число должно быть избавлено от дробной части. Вариантов у нас, собственно говоря, два: преобразование путём отбрасывания дробной части и путём математического округления; для первого варианта используется встроенная функция trunc, для второго — round. Например, если у нас есть три переменные:
![]()
то после выполнения присваиваний
![]()
в переменной i будет число 15 (результат “тупого” отбрасывания дробной части), а в переменной j — число 16 (результат округления к ближайшему целому). На самом деле функции round и trunc производят не преобразование типа, а некое вычисление, ведь в общем случае (при ненулевой дробной части) полученное значение отличается от исходного. К разговору о преобразованиях типов эти функции имеют лишь опосредованное отношение: было бы не совсем честно заявить, что соответствующее неявное преобразование запрещено, и при этом не объяснить, что делать, если оно всё-таки потребовалось.
Отметим один немаловажный момент. Неявным преобразованим могут подвергаться значения выражений, но не переменные; это означает, что при передаче переменной в подпрограмму через var-параметр тип переменной должен точно совпадать с типом параметра, никакие вольности тут не допускаются; например, если ваша подпрограмма имеет var-параметр типа integer, то вы не сможете передать ей переменную типа longint, или типа word, или любого другого — только integer. Это имеет простое объяснение: машинный код подпрограммы сформирован в расчёте на переменную типа integer и при этом ничего не знает и не может знать о том, что на самом деле произошло в точке вызова, так что, если бы вместо integer компилятор допускал передачу, например, переменной типа longint, подпрограмма никак не могла бы узнать, что ей подсунули переменную не того типа. С преобразованиями значений (в отличие от переменных) всё гораздо проще: все преобразования компилятор делает в точке вызова, а тело подпрограммы получает уже именно тот тип, которого ждёт.
Кроме неявных преобразований, Free Pascal33 поддерживает также явные преобразования типов, причём такие преобразования возможны как для значений выражений, так к для переменных. Слово “явный” здесь означает, что программист сам — в явном виде — указывает, что вот здесь необходимо преобразовать выражение к другому типу или временно считать некую переменную имеющей другой тип. В Паскале синтаксис такого явного преобразования напоминает вызов функции с одним параметром, но вместо имени функции указывается имя типа. Например, выражения integer(5) и byte(5) оба будут иметь целочисленное значение 53, в первом случае это будет двухбайтное знаковое, во втором — однобайтовое беззнаковое. Точно так же мы можем описать переменную типа char и временно рассмотреть её в роли переменной типа byte:

Конечно, далеко не любые типы можно преобразовать друг в друга. Free Pascal разрешает явные преобразования в двух случаях: (1) порядковые типы можно преобразовывать друг в друга без ограничений, причём это касается не только целых чисел, но и char, и boolean, и перечислимых типов; и (2) можно преобразовать друг в друга типы, имеющие одинаковый размер машинного представления. Что касается преобразования типов переменных, то первый случай для них не работает и требуется обязательное совпадение размеров.
С явными преобразованиями типов следует соблюдать определённую осторожность, поскольку происходящее не всегда будет совпадать с вашими ожиданиями. Например, код символа лучше всё же получать с помощью функции ord, а создавать символ по заданному коду — с помощью chr, которые специально для этого предназначены. Если вы не совсем уверены, что вам нужно явное преобразование типов, или знаете, как без него обойтись — то лучше вообще его не применять. Заметим, что обойтись без таких преобразований можно всегда, но в некоторых сложных ситуациях возможность сделать преобразование позволяет сэкономить трудозатраты; иной вопрос, что столь заковыристые случаи вам ещё очень долго не встретятся.