Информатика - Новый полный справочник для подготовки к ОГЭ
Кодирование информации. Принцип двоичного кодирования. Кодирование текстовой, графической, звуковой информации - Запись средствами ИКТ информации об объектах и о процессах окружающего мира - ИНФОРМАЦИОННЫЕ И КОММУНИКАЦИОННЫЕ ТЕХНОЛОГИИ
Конспект
При хранении и обработке информации на компьютере используется двоичная система счисления. Это значит, что любая обрабатываемая компьютером информация кодируется при помощи двоичных кодов. Рассмотрим, как это происходит для различных типов информации.
Целые неотрицательные числа переводятся в двоичную систему счисления и именно в этом виде записываются. Следует только понимать, что любая информация на компьютере записывается в ячейки определённого размера. Размер ячейки составляет некоторое количество байт (напомним, байт = 8 бит). Чаще всего используют размеры в 1, 2, 4 и 8 байт (как видите, в компьютере даже размеры ячеек принято делать равными какой-нибудь степени числа 2). То есть, целое неотрицательное число хранится в ячейке из некоторого количества бит (обычно 8, 16, 32, 64 бита соответственно). Это значит, что хранимые на компьютере числа не могут быть любыми, произвольного размера. Размер максимального хранимого числа зависит от размера ячейки, в которой это число хранится. В ячейке размером n бит можно хранить максимальное неотрицательное число — 2n - 1.
Например, в ячейке размером 8 бит максимальное неотрицательное число, которое можно сохранить — это 255 (= 28 - 1).
Несколько сложнее хранятся числа со знаком. Из всех бит, которые выделяются для хранения числа, один бит выделяется для хранения знака числа (0 — число положительное, 1 — число отрицательное). Таким образом, для хранения значения числа остаётся на 1 бит меньше. То есть, наибольшее знаковое число, которое хранится в ячейке размером n, — это 2n-1 - 1.
Например, в ячейке размером 16 бит можно хранить числа до 32767 (= 216-1 - 1).
Для хранения вещественных чисел используется более хитрая технология. Изучение этой темы не входит в курс основной школы.
При кодировании других видов информации используется примерно такой принцип: придумывается, как пронумеровать все возможные состояния, которые нужно хранить (т. е. в соответствие каждому хранимому состоянию ставится определённый числовой номер-код). Потом коды переводятся в двоичную систему счисления и хранятся в виде двоичных чисел.
Кодирование текстовой информации
Все символы, которые собираются использовать для записи текста, выписываются в ряд и нумеруются последовательными целыми неотрицательными числами, начиная с нуля. Это получило название кодовой таблицы символов.
Самая распространённая кодовая таблица символов называется ASCII (American standard code of Information Interchange — американский стандартный код обмена информации. Принято читать это как “Аски”).
Изначально данный код был придуман как 7-мибитный (8-й бит использовался для контроля чётности, так как в те времена были очень частые ошибки хранения и передачи информации). Поэтому кодовая таблица содержала в себе только 27 = 128 различных символов. Подобная таблица получила название базовой таблицы ASCII. Она содержит в себе только латинские символы (строчные и прописные), цифры, знаки препинания и служебные символы.
Впоследствии методы хранения и передачи информации стали существенно лучше и появилась возможность использовать дополнительный (восьмой) бит, что сразу увеличило количество возможных хранимых знаков вдвое, до 256 (28 = 256). Эту вторую половину таблицы ASCII стали называть дополнительной таблицей ASCII. А всю 8-битную таблицу — расширенной таблицей ASCII.
Именно среди 128 дополнительных символов и находятся коды большинства национальных алфавитов, в том числа и кириллица, которой мы пользуемся.
К сожалению, при появлении дополнительной таблицы ASCII разные производители операционных систем не смогли (или не сочли нужным) договориться и придумали свои, различные способы распределения символов кириллицы по 128 кодам дополнительной таблицы. Больше всего “отличилась” фирма Microsoft, которая придумала целых 2 способа этого кодирования.
На данный момент имеется 5 способов хранения кириллицы:
|
КОИ8 (код обмена информации 8-битный) |
Используется в основном в Unix-подобных системах. |
|
MS-DOS |
Используется в операционной системе MS DOS. |
|
Windows-1251 |
Используется в операционных системах MS Windows. |
|
MAC |
Используется в операционных системах MAC OS. |
|
ISO |
Попытка стандартизировать все предыдущее не получила широкого распространения. |
Способ применения дополнительной таблицы задаётся для всего текста. Используя ASCII, невозможно одновременно увидеть текст, например, на русском и на французском языках, потому что оба языка применяют примерно одни и те же коды дополнительной таблицы ASCII. То есть, последовательность кодов следует трактовать либо как русский, либо как французский язык. То же обстоятельство приводит к тому, что иногда на компьютере отображается текст из кириллицы, выглядящий как полная абракадабра. Это связано с тем, что для просмотра текста используется неверная кодовая таблица (либо, что ещё хуже, текст в процессе передачи несколько раз перекодировался из одной кодировки в другую).
Для решения задач на кодирование текста важно знать золотое правило — независимо от используемой кодировки таблицы ASCII, одному символу соответствует один байт (8 бит).
Для таблицы ASCII: 1 символ = 1 байт!
Чтобы кардинально решить проблему однозначного кодирования букв всех (практически) алфавитов и стандартизировать кодовые таблицы, в начале 1990-х годов был предложен иной способ кодирования текста — Unicode (Юникод). В нём разработчики решили пожертвовать количеством ради качества — использовать для хранения не один байт, а два, т. е. получить 216 = 65536 различных символов. Это, с одной стороны, увеличило вдвое объём памяти, необходимый для хранения текстов, а также время, необходимое для их передачи. С другой стороны, убрало все вышеуказанные проблемы и противоречия.
В действительности, Юникод не всегда использует именно 2 байта для хранения кодов символов. Но в рамках основного образования по информатике мы предлагаем считать, что это так. Во всяком случае, в задачах экзамена (ОГЭ), к которому мы надеемся этой книжкой подготовить вас, дорогой читатель, вам встретится именно двухбайтовое кодирование в Юникоде.
Кодирование графической информации
При хранении на компьютере изображений различают два основных способа — растровый и векторный.
При растровом способе изображение хранится в виде прямоугольного массива точек. Эти точки обычно называют пикселями(pixel от pictel — picture element — элемент изображения). Каждый пиксель весьма мал, пикселей много, и они находятся близко друг к другу. Человек обычно не различает их по отдельности, а воспринимает всю картинку целиком. Такой способ хранения изображения как правило получается при использовании фотоаппаратов или сканеров. Подобные устройства разбивают изображения реальных объектов на прямоугольный набор точек-пикселей и запоминают цвет каждого пикселя.
Второй способ хранения изображений — векторный. При этом изображение хранится в виде отдельных объектов — прямоугольников, эллипсов, линий, кривых разной формы, каждый из которых закрашен определённым образом. Картинка при этом получается менее реалистичной, чем окружающий нас мир, зато такие изображения проще изменять, масштабировать, преобразовывать. Проверка способов кодирования векторных изображений не входит в текущую версию ОГЭ, и мы не будем их далее рассматривать.
Кодирование цвета.
При кодировании изображений важное значение имеет способ кодирования цвета. Самый простой способ — сделать так же, как при кодировании символов. То есть, выписать в столбик все возможные цвета, пронумеровать и хранить эти номера как коды цвета. Данный способ хорош до тех пор, пока количество различных цветов не очень большое. Например, 16 или 256. Такая технология существует и используется, но только для указанного небольшого количества цветов в изображении. Обычно изображение состоит из гораздо большего количества цветов.
Считается, что обычный человеческий глаз способен различить 16 миллионов оттенков цвета. Соответственно, хотелось бы сопоставить всем (или почти всем) этим цветам свои коды. Только хранить таблицу из 16 миллионов оттенков цвета очень неудобно. Поэтому используется другая технология, которая называется цветовая модель. Цветовая модель — это способ представления цвета при помощи нескольких базовых цветов. Смешивая оттенки различной яркости базовых цветов можно получить все возможные цвета, которые способна хранить цветовая модель.
Наиболее известной цветовой моделью является цветовая модель RGB. Её название состоит из первых букв трёх базовых цветов этой модели — Red, Green, Blue (красный, зелёный, синий). Смешивание именно этих трёх цветов позволяет получить любой из 16,7 миллионов цветов, который умеет хранить цветовая модель RGB.
В этой цветовой модели работают такие окружающие нас электронные устройства, как телевизоры, сканеры, мониторы (в том числе мобильных телефонов и планшетов), проекторы, фотоаппараты. То есть, все устройства, которые получают картинку по принципу светящихся точек. Так, чёрная (изначально) поверхность подсвечивается очень маленькими точками трёх базовых цветов — красного, зелёного и синего. Эти три точки расположены очень близко к друг другу и каждая из них может светиться различным оттенком яркости — от нуля до максимума (255). Именно три точки базовых цветов и образуют те элементы изображения (пиксели), из которых состоит растровая картинка.
Так как при восприятии человеческим глазом яркости базовых цветов складываются, то эта цветовая модель называется яркостной или, по-другому, аддитивной (от английского add — складывать).
Не все компьютерные устройства работают в цветовой модели RGB. Например, принтеры работают в цветовой модели CMYK. Точки базовых цветов наносятся на белую поверхность (например, бумагу) и каждая из них поглощает какое-то количество спектра белого света, который на бумагу падает. Отражённые оттенки спектра мы и видим. Данная модель — субтрактивная(вычитательная, от subtract — вычитать). Цвет вычитается из белого света.
Проверка кодирования цвета в цветовых моделях, отличных от RGB, не входит в ОГЭ по информатике.
Для понимания того, какой цвет получится в цветовой модели RGB при сложении базовых цветов (они называются компонентами), нужно понимать принцип сложения и цветовой шестиугольник.
Принцип сложения цветов в модели RGB состоит в том, что исходная поверхность — чёрная. То есть, если все три компоненты не будут светиться (будут равны нулю), то получится чёрный цвет.
Если же, наоборот, все три компоненты будут светиться по максимуму, то получится максимальная яркость — белый цвет.
Когда все три компоненты будут одинаковыми, получается один из оттенков серого цвета — от чёрного (все три нуля) до белого (все три 255).
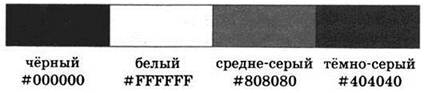
Для обозначения кодов цвета принято использовать запись яркостей всех трёх компонент — RGB — в шестнадцатеричной системе счисления двухразрядными числами. Нулевая яркость записывается как 00, средняя яркость — как 80, а максимальная яркость — как FF. Перед кодом цвета принято ставить значок решетки #.
Таким образом, код чёрного цвета будет #000000, код белого цвета — #FFFFFF, код средне-серого цвета — #808080, а код тёмно-серого — #404040.
Например:
Нетрудно понять, что красный цвет — это максимум красной компоненты и остальные 0. То есть, #FF0000. Соответственно, зелёный — #00FF00, а синий — #0000FF.
При необходимости сделать более тёмный цвет, нужно уменьшить общую яркость. Например, тёмно-красный — #800000.
Если требуется сделать более светлый цвет, то нужно, соответственно, увеличить общую яркость.
Однако в случае, например, с красным цветом, яркость красной компоненты уже установлена на максимум. Значит, следует увеличивать яркость других компонент, причём одновременно, т. е. светло-красный будет, например, #FF8080.
Остальные цвета получаются более хитро — смешиванием компонент в разных пропорциях. Для вопросов, которые могут возникнуть на экзамене, достаточно понимать основные цвета на цветовом шестиугольнике:
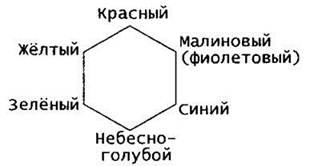
Из него видно, что смешение красного и синего цвета даст малиновый, а смешение красного и зелёного цвета — жёлтый. Соответственно, для того, чтобы получить цвет, лежащий между указанными, нужно взять базовые цвета в соответствующей пропорции. Так, например, оранжевый цвет лежит посередине между красным и жёлтым. Красный — #FF0000, жёлтый — #FFFF00. Значит, для получения нужного оранжевого следует брать среднее арифметическое по каждой компоненте. Получаем, что красного нужно взять (FF + FF)/2 = FF, зелёного (00 + FF)/2 ≈ 80, синего (00 + 00)/2 = 00. То есть, оранжевый — #FF8000.
Исходя из всего вышеизложенного, запомните, что для хранения изображения в цветовой модели RGB используется 3 раза по 8 бит (для каждой компоненты), то есть, всего 3 байта или 24 бита.
Вычисление объёма растрового изображения.
При хранении на компьютере растровых изображений (если не применяются методы сжатия информации) используется следующий принцип: для каждого пикселя хранится его код. Количество пикселей во всем изображении — это количество пикселей по ширине, умноженное на количество пикселей по высоте. Так как все пиксели для своего представления используют одинаковое количество бит, получаем формулу для расчёта объёма растрового изображения:
![]()
где V — объём неупакованного растрового изображения (в байтах), Н и W — ширина и высота растрового изображения (в пикселях), i — количество бит, которое тратится на один пиксель.
Так как объём изображения принято измерять в байтах, а объём памяти, выделяемый для одного пикселя — в битах, правая часть выражения делится на 8.
Кодирование звука
Для понимания принципов кодирования звука лучше всего для начала усвоить принцип работы цифрового микрофона, т. е. как компьютер получает от окружающего мира звуковую информацию. В микрофоне установлена мембрана — тоненькая плёнка, которая способна отклоняться от своего среднего (нейтрального) положения при колебаниях окружающего воздуха. Не будем вдаваться в функционирование этого явления с физической точки зрения. Для нас важно, что отклонения этой мембраны можно записывать в цифровом виде много раз в секунду. Количество измерений в секунду называется частотой дискретизации. Например, 40 тысяч раз в секунду происходит измерение текущего отклонения мембраны. Говорят, что частота дискретизации при этом — 40 кГц, а значение отклонения мембраны от нейтрального положения записывают при помощи определённого количества бит. Чем это значение больше, тем точнее будет запись звука. Правило кодирования следует из формулы Хартли: 2количество_бит = количество_различных_значений отклонения мембраны. Эти различные значения называют уровнями квантования.
Ещё нужно понимать, что звук зачастую записывается мультиканальный. То есть, когда запись идёт только с одного микрофона, это называется моно. Когда с двух микрофонов — стерео. Иногда используют большее количество каналов. Например, квадро (4) или даже 7.1 (8 каналов).
Итак, при кодировании звука происходит запись по каждому каналу с определённой частотой дискретизации в течение определённого времени. Для каждого измерения используется определённое количество бит.
Получаем формулу для вычисления объёма неупакованного звукового файла:
![]()
где V — объём неупакованного звукового файла (в байтах), Ch — количество каналов (1 — моно, 2 — стерео, 4 — квадро, и т. д.), v — частота дискретизации, i — количество бит на одно измерение (разрешение), t — время записи в секундах. Так как левая часть — в байтах, а правая — в битах, правую часть делим на 8.
Разбор типовых задач
Вычисление объёма текстовой информации
Задача 1. В одной из кодировок Unicode каждый символ кодируется 16 битами.
Определите размер следующего предложения в данной кодировке:
Я к вам пишу — чего же боле? Что я могу ещё сказать?
1) 52 байт
2) 832 бит
3) 416 байт
4) 104 бит
Решение
В этой задаче используется простая формула для вычисления количества информации в сообщении: I = k ∙ i. Для её использования необходимо знать количество информации в одном символе (дано — 16 бит) и количество символов в сообщении. Важно понимать, что под символами имеются ввиду не только печатаемые символы, но ещё и пробелы, их тоже требуется передавать. Значит, для каждого из них будем использовать те же 16 бит, что и для остальных символов. Аккуратно посчитаем количество символов в приведённом сообщении, включая пробелы и знаки препинания. Подсчитываем, и получаем 52.
Подставляем в формулу: I = 52 ∙ 16 = 832 бит.
Ответ: 2.
Если бы в списке предлагаемых вариантов ответа не было бы этого значения — 832 бит, имело бы смысл поискать ответ в виде количества байт. То есть, 52 ∙ 2 = 104 байт.
Задача 2. Некоторый текст, изначально записанный в кодировке КОИ-8, был перекодирован и записан в 16-битной кодировке Unicode. Известно, что в процессе этого перекодирования объём текста, занимаемый им на диске, увеличился на 640 бит. Определите количество символов в тексте. Ответ запишите в виде числа.
Решение
В процессе перекодирования текста количество символов в нём не изменяется. Обозначим количество символов в тексте через k. Найдём количество бит, которое занимал текст до перекодирования. Воспользуемся известной формулой для вычисления количества информации в сообщении: I = k ∙ i. Для её использования необходимо знать количество бит, затраченное на один символ. По условию известно, что текст записан в кодировке КОИ-8. Отсюда мы понимаем, что это разновидность таблицы ASCII. Следовательно, один символ кодируется 8-ю битами. Считаем объём информации в сообщении: I = 8 ∙ k.
Теперь посчитаем объём информации в перекодированном тексте.
По этой же формуле получаем I = 16 ∙ k. Найдём изменение этого количества. Вычтем из полученного объёма исходный: 16/е - 8k = 8k.
В условии объём текста увеличился на 640 бит. Это по нашим расчётам 8k. Приравняем эти две величины и находим отсюда k: 8k = 640 → k = 640 / 8 = 80 символов.
Ответ: 80.
Данную задачу можно было решить проще. В процессе перекодирования каждый символ из исходных 8-ми бит (таблица ASCII) стал кодироваться 16-ю битами (Юникод), т. е. занимать на 8 бит больше. Так как весь текст увеличился на 640 бит, можно найти, сколько было символов:
640 / 8 = 80.
Вычисление объёма растрового изображения.
Задача 3. Какой объём на диске (в Мбайт) занимает неупакованное растровое изображение размером 1024x2048 пикселей, если для хранения кода цвета используется 16 бит.
Решение
Подставим имеющиеся данные в формулу: ![]() Так как ответ нужно дать в Мбайт, а величина V по этой формуле вычисляется в байтах, нужно величину V перевести в Мбайты. То есть, поделить дважды на 1024. Получится ответ: 4.
Так как ответ нужно дать в Мбайт, а величина V по этой формуле вычисляется в байтах, нужно величину V перевести в Мбайты. То есть, поделить дважды на 1024. Получится ответ: 4.
Ответ: 4.
Может так случиться, что в задаче не будет явно указано количество бит, которое используется для кодирования цвета одного пикселя. При этом будет указано максимальное количество цветов, которое используется в данном изображении. В таком случае, для вычисления количества бит, которое требуется для кодирования цвета пискеля, необходимо воспользоваться уже знакомой нам формулой Хартли: 2i ≥ N.
В качестве количества равновероятных событий здесь выступает максимальное количество цветов изображения. То есть, видоизменение формулы Хартли применительно к подобной задаче будет иметь вид: 2число_бит ≥ число_цветов_в_изображении.
Задача 4. На диске хранится неупакованное 16-цветное изображение размером 512x4096 пикселей. Какой объём на диске оно занимает? Считать, что для хранения кода пикселя используется минимально возможное количество бит. Ответ укажете в Мбайт.
Решение
Сразу воспользоваться формулой V = Н ∙ W ∙ i / 8 мы не можем, потому что нам не известно i — количество бит, используемое для хранения кода одного пикселя. Найдём это количество, используя формулу Хартли: 2число_бит ≥ 16 → Число бит i = 4. Теперь у нас есть значения всех параметров, которые нужно подставить в формулу: ![]()
![]() Переводим эту величину в Мбайты. Для этого поделим её на 220.
Переводим эту величину в Мбайты. Для этого поделим её на 220.
Ответ'. 1.
Кодирование звука.
Задача 5. Происходит четырёхканальная запись звука с частотой дискретизации 4 кГц и разрешением 16 бит. Запись длится полминуты. Определите ближайшее целое количество Мбайт, которое нужно примерно потратить на диске для хранения неупакованного звукового файла. В ответе запишите только число.
Решение
Подставим величины в формулу: ![]() Переводим полученную величину в Мбайты: 960 000 / (1024 ∙ 1024). Данная величина чуть меньше 1. Значит, округляем до ближайшего целого и получаем ответ: 1.
Переводим полученную величину в Мбайты: 960 000 / (1024 ∙ 1024). Данная величина чуть меньше 1. Значит, округляем до ближайшего целого и получаем ответ: 1.
Ответ: 1.
Иногда в задаче может быть не указано разрешение записи. Вместо этого будет указано количество уровней квантования. В этом случае необходимо сначала найти разрешение по формуле Хартли: 2i ≥ N, где i — разрешение записи (в битах), N — количество уровней квантования.
Задача 6. Производится двухканальная (стерео) звукозапись с частотой дискретизации 16 кГц. При записи используется количество уровней квантования, равное 32. Запись длится 30 минут, её результаты записываются в файл, сжатие данных не производится. Определите объём полученного звукового файла в Мбайт. В качестве отчета укажите ближайшее число, кратное 5.
Решение
В данном случае нам не дано разрешение, с которым производится запись. Найдём его, зная количество уровней квантования: 2i ≥ 32 → i = 5.
Теперь подставим все полученные величины в формулу объёма звукового файла: ![]()
![]() Преобразуем полученную величину в Мбайты: 36 000 000 / (1024 ∙ 1024). Ближайшая полученная величина, кратная 5 = 35.
Преобразуем полученную величину в Мбайты: 36 000 000 / (1024 ∙ 1024). Ближайшая полученная величина, кратная 5 = 35.
Ответ: 35 Мбайт.